文末附完整的记忆规则代码,看完即可直接复用。
一个真实的数据对比
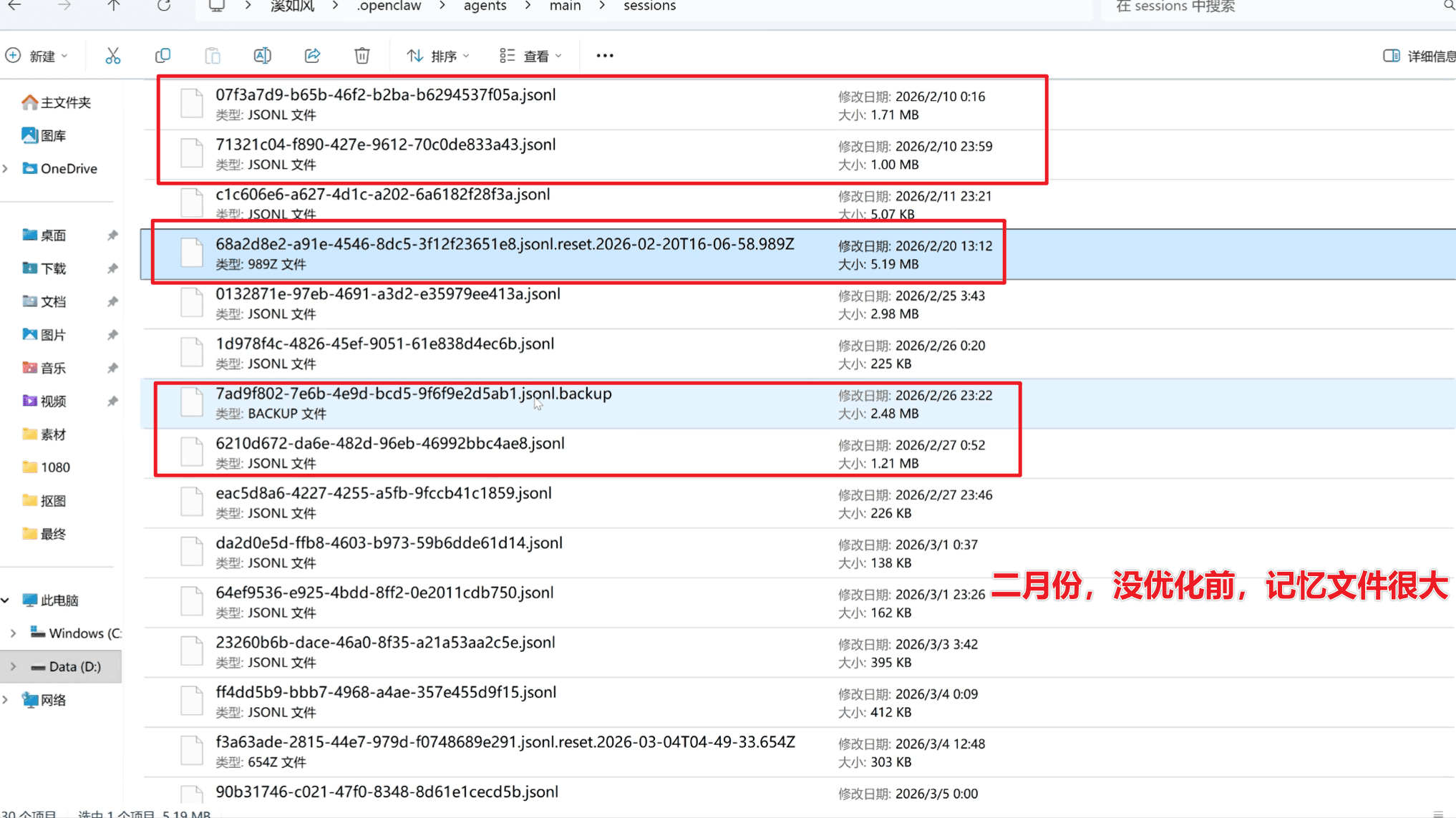
这是我的会话记录。
你看 2 月 10 日,一个 1.71MB,一个 1MB。后面几天更大——2 月 25 日 2.98MB,2 月 26 日 2.48MB。这些都是优化前的。
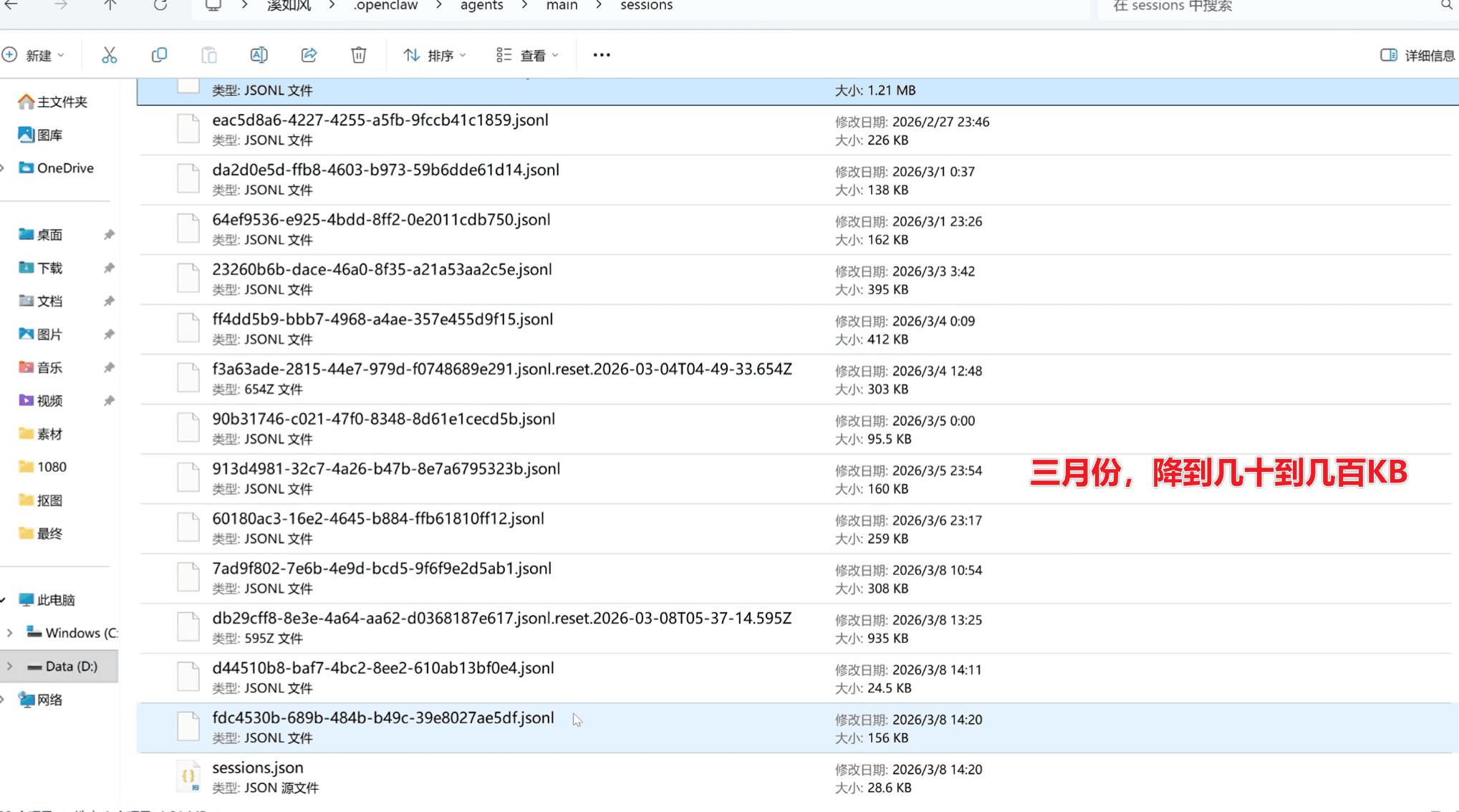
现在呢?3 月份的会话,降到几十到几百 KB。
我是怎么做到的?
问题出在哪?
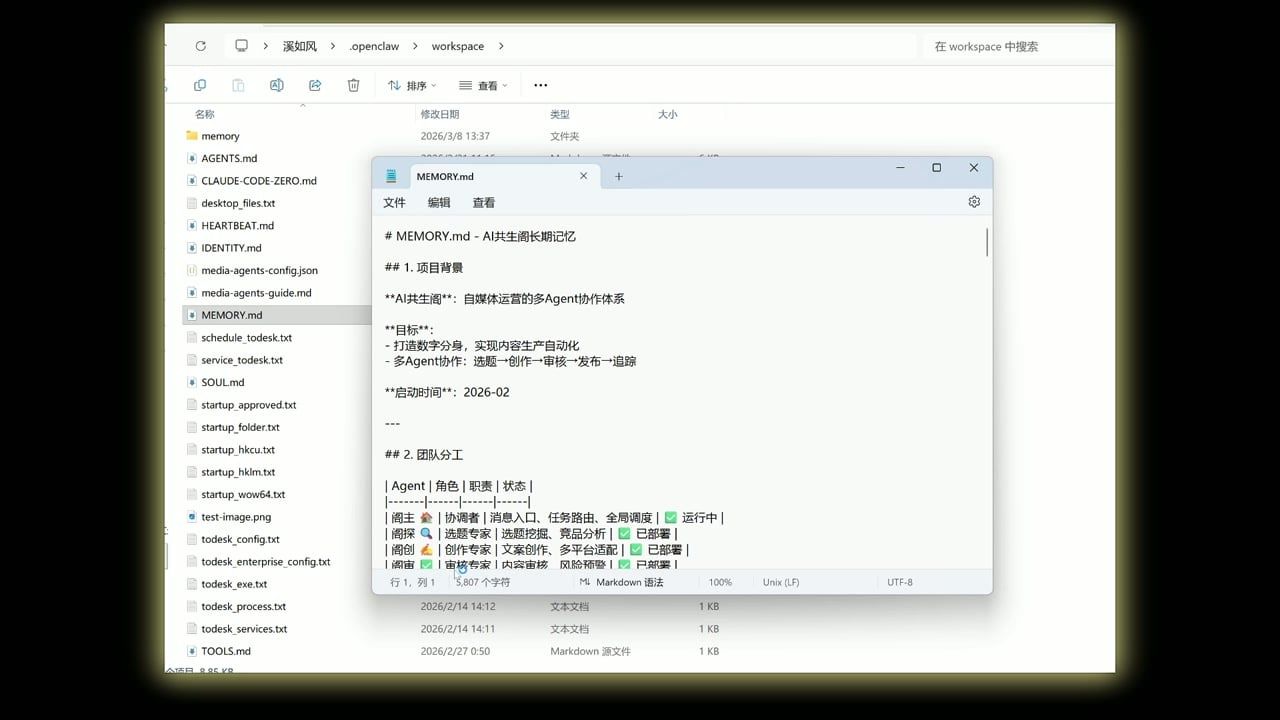
我的记忆文件有 5800 多字符,全量加载要 3000 多 Token。
每次对话都加载一遍,这就像找资料把整个图书馆搬回家。
第一招:QMD 模式
在 AGENTS.md 里,我写好了记忆访问规范。
核心原则是:按需检索,不全量加载。
具体怎么用?
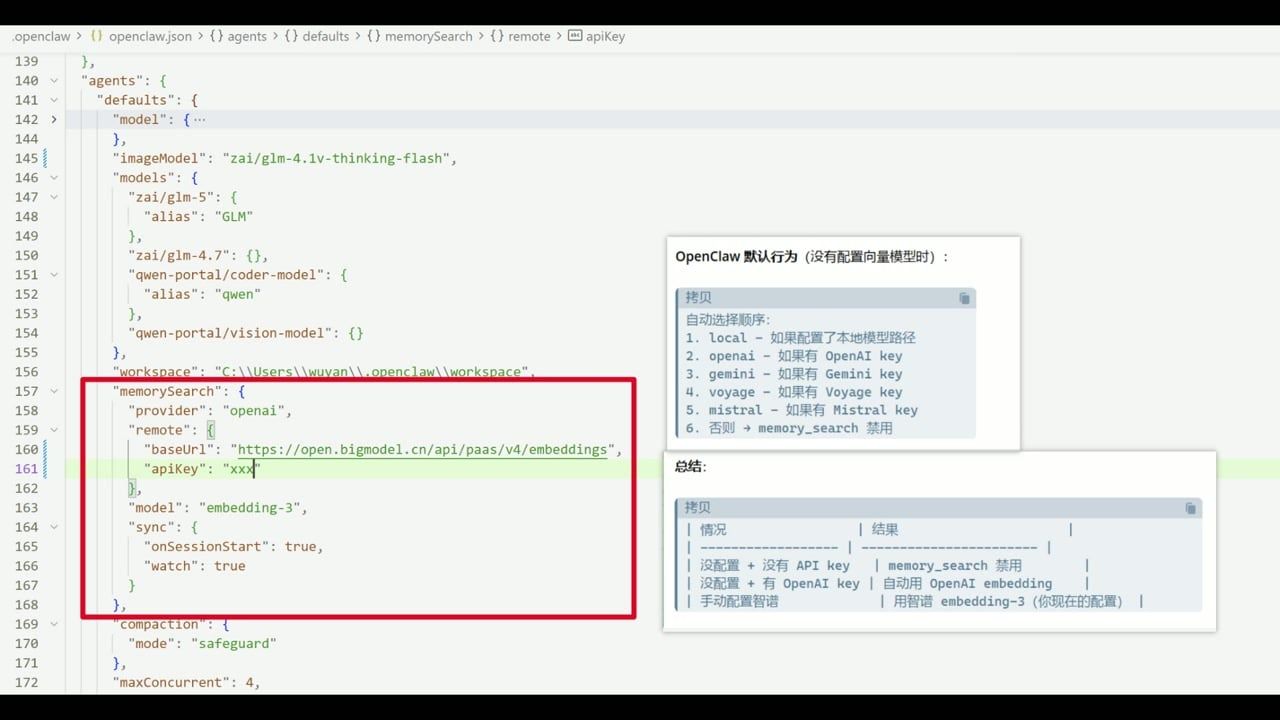
我在 OpenClaw 里配置了智谱的 embedding-3 模型做向量化检索。
选智谱是因为:
- ✅ 中文友好
- ✅ 性价比高
OpenClaw 也支持 OpenAI、Gemini 等其他向量服务。
用 OpenClaw 自带的 memory_search 输入关键词,系统会在 MEMORY.md 和所有日志文件里搜索,找到最相关的片段。
再用 memory_get 精确读取需要的行。
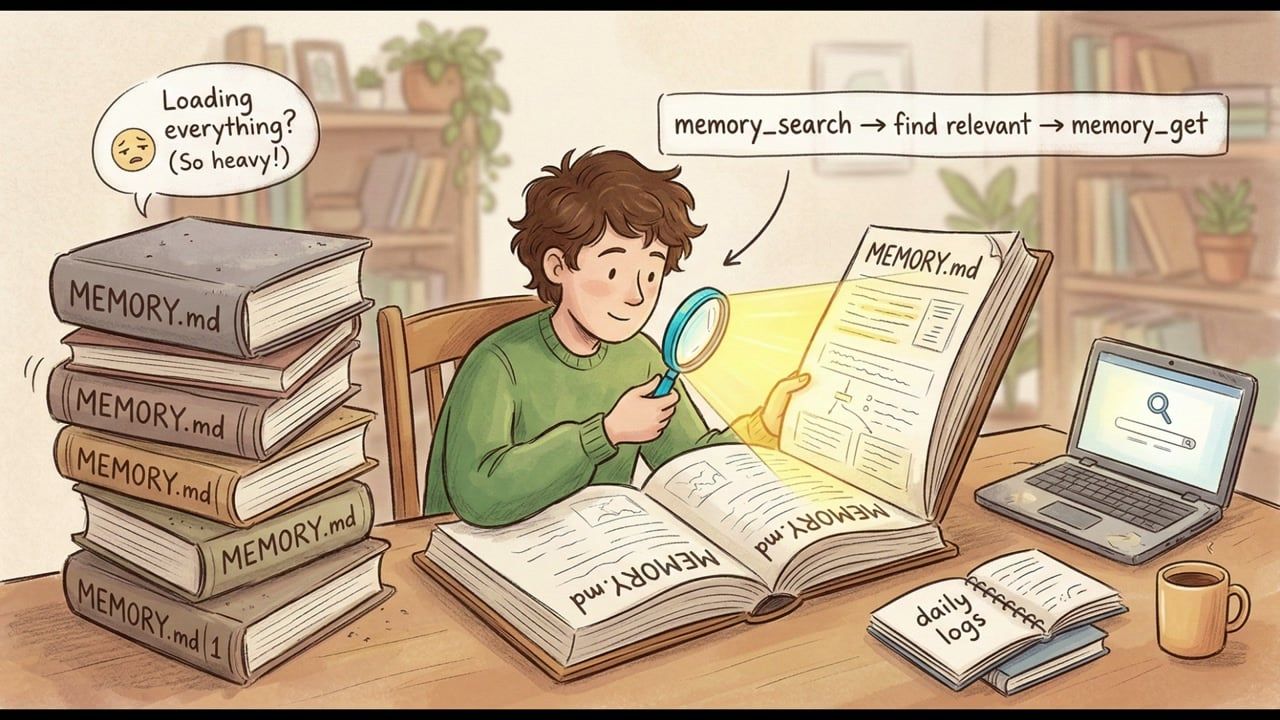
不用全量加载,省掉 80-90% Token。
第二招:精简记忆
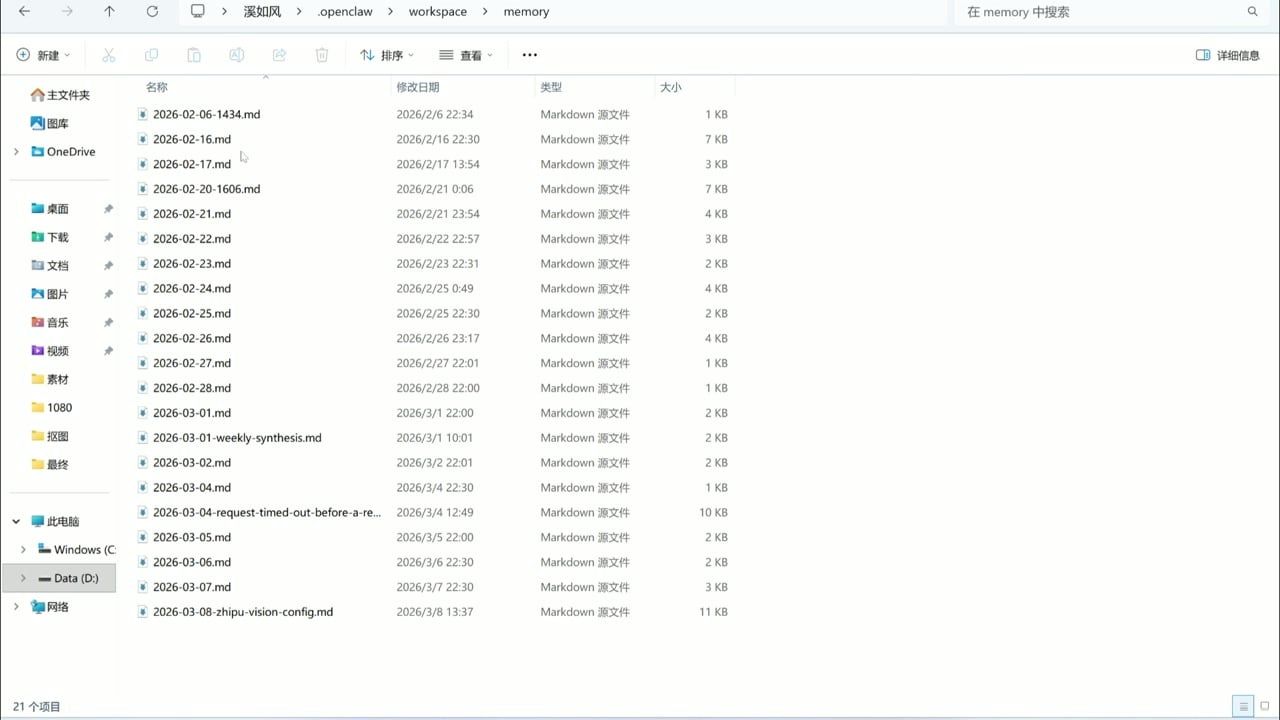
你看这里有 20 多个日志文件——我在 AGENTS.md 里设置了定时任务:
- 每天结束后自动沉淀一份日志
- 定期合成到主记忆文件里
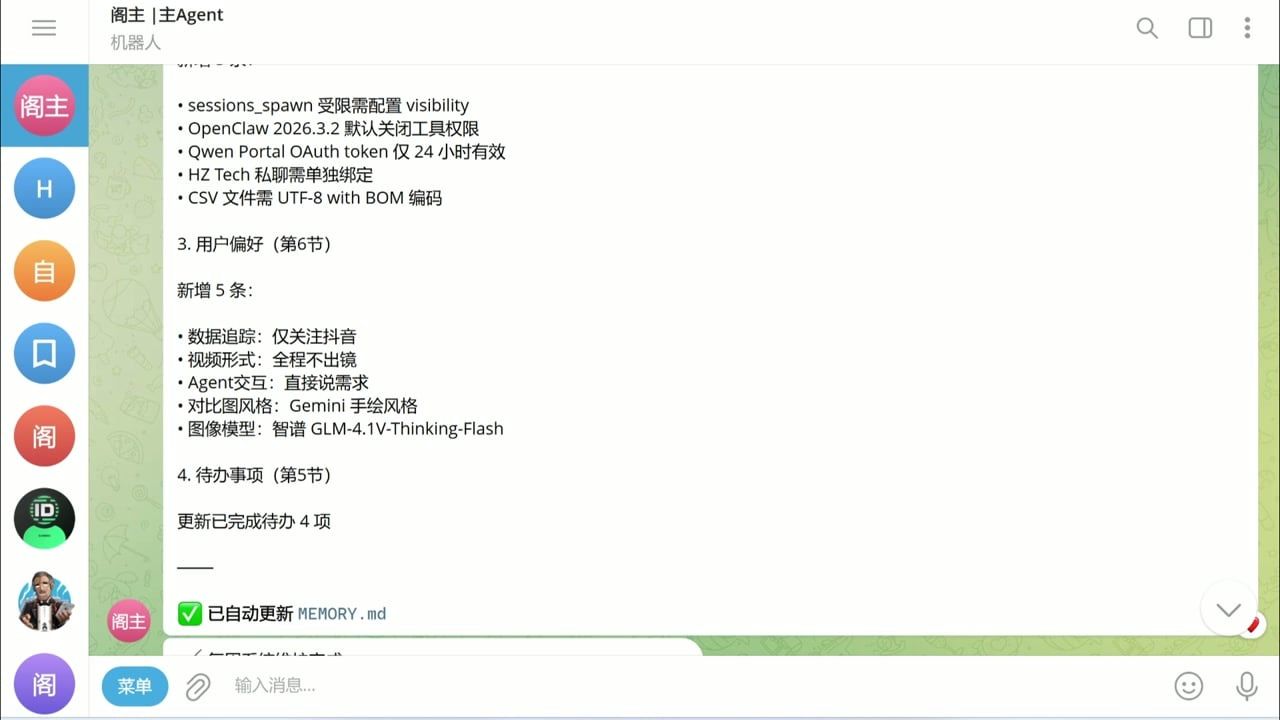
这样 MEMORY.md 就不会越来越臃肿。
总结:2 招省掉 80-90% Token
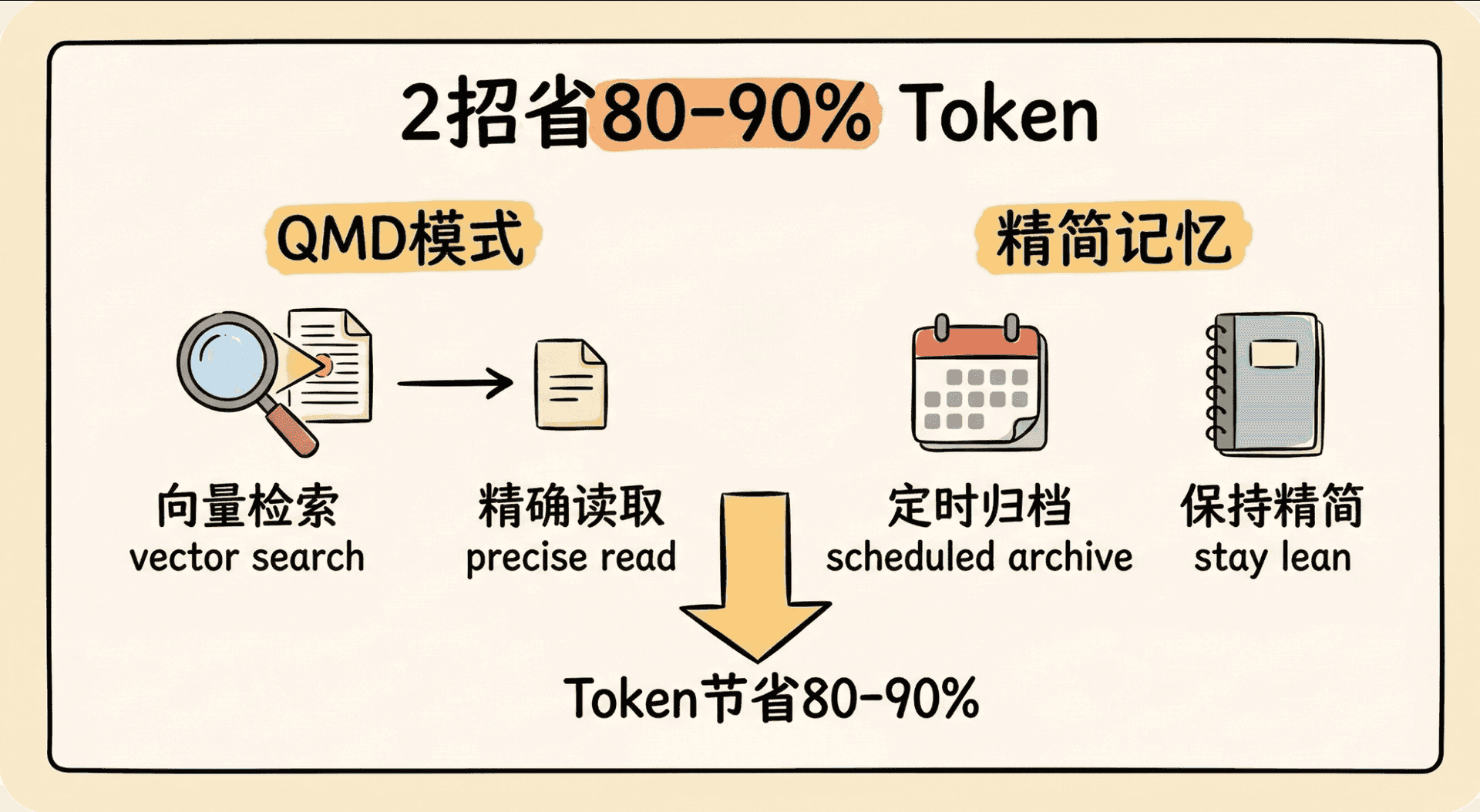
| 招数 | 核心原理 | 效果 |
|---|---|---|
| QMD 模式 | 向量检索 + 精确读取 | 省掉 80-90% Token |
| 精简记忆 | 定时归档 + 保持精简 | 防止记忆膨胀 |
写在最后
如果你也在用 OpenClaw,这 2 招能帮你省下大量 Token。
关注我,后续分享更多 OpenClaw 实战技巧。
这里是 AI 共生阁,我们下期见~
附录 - ~.openclaw\workspace\AGENTS.md 的记忆规则
